

获取全站用户,理论来说从1个用户作为切入点就可以,我们需要爬取用户的关注列表,从关注列表不断的叠加下去。
随便打开一个用户的个人中心
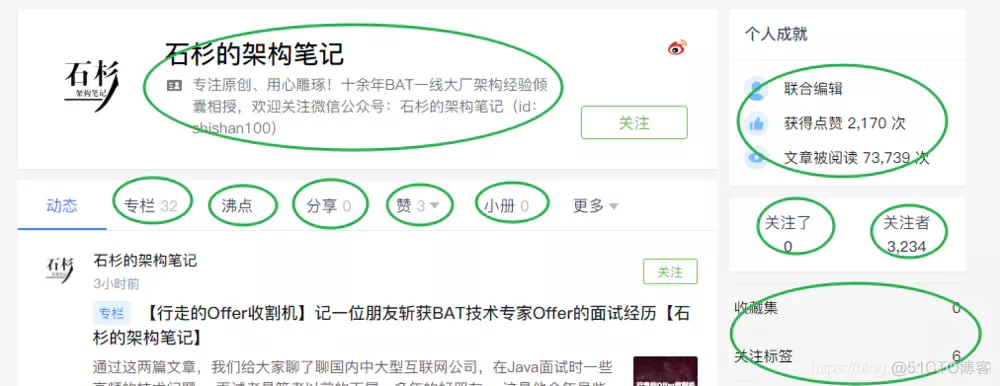
绿色圆圈里面的都是我们想要采集到的信息。这个用户关注0人?那么你还需要继续找一个入口,这个用户一定要关注了别人。选择关注列表,是为了让数据有价值,因为关注者里面可能大量的小号或者不活跃的账号,价值不大。
我选了这样一个入口页面,它关注了3个人,你也可以选择多一些的,这个没有太大影响! https://juejin.im/user/55fa7cd460b2e36621f07dde/following 我们要通过这个页面,去抓取用户的ID
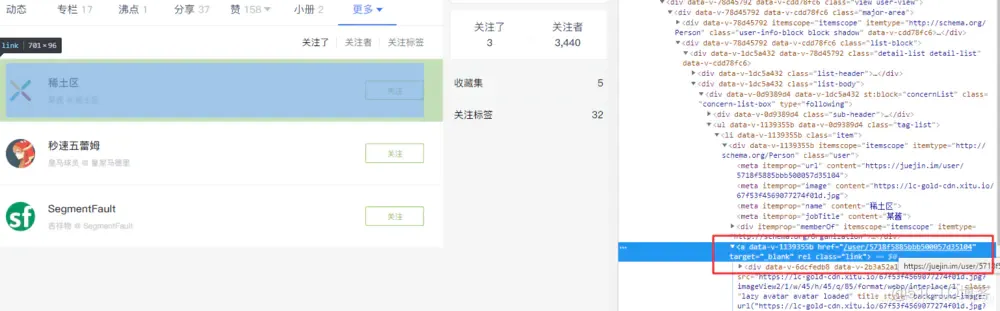
得到ID之后,你才可以拼接出来下面的链接
https://juejin.im/user/用户ID/following
爬虫编写
分析好了之后,就可以创建一个scrapy项目了
items.py 文件,用来限定我们需要的所有数据,注意到下面有个_id = scrapy.Field() 这个先预留好,是为了mongdb准备的,其他的字段解释请参照注释即可。
class JuejinItem(scrapy.Item):
_id = scrapy.Field() username = scrapy.Field() job = scrapy.Field() company =scrapy.Field() intro = scrapy.Field() # 专栏 columns = scrapy.Field() # 沸点 boiling = scrapy.Field() # 分享 shares = scrapy.Field() # 赞 praises = scrapy.Field() # books = scrapy.Field() # 关注了 follow = scrapy.Field() # 关注者 followers = scrapy.Field() goods = scrapy.Field() editer = scrapy.Field() reads = scrapy.Field() collections = scrapy.Field() tags = scrapy.Field() Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
编写爬虫主入口文件 JuejinspiderSpider.py
import scrapy from scrapy.selector import Selector from Juejin.items import JuejinItem
class JuejinspiderSpider(scrapy.Spider): name = ‘JuejinSpider’ allowed_domains = [‘juejin.im’] # 起始URL 5c0f372b5188255301746103 start_urls = [‘https://juejin.im/user/55fa7cd460b2e36621f07dde/following’]
def parse 函数,逻辑不复杂,处理两个业务即可
item的获取,我们需要使用xpath匹配即可,为了简化代码量,我编写了一个提取方法,叫做get_default函数。
def get_default(self,exts): if len(exts)>0: ret = exts[0] else: ret = 0 return ret
def parse(self, response): #base_data = response.body_as_unicode() select = Selector(response) item = JuejinItem() # 这个地方获取一下数据 item["username"] = select.xpath("//h1[@class=’username’]/text()").extract()[0] position = select.xpath("//div[@class=’position’]/span/span/text()").extract() if position: job = position[0] if len(position)>1: company = position[1] else: company = "" else: job = company = "" item["job"] = job item["company"] = company item["intro"] = self.get_default(select.xpath("//div[@class=’intro’]/span/text()").extract()) # 专栏 item["columns"] = self.get_default(select.xpath("//div[@class=’header-content’]/a[2]/div[2]/text()").extract()) # 沸点 item["boiling"] = self.get_default(select.xpath("//div[@class=’header-content’]/a[3]/div[2]/text()").extract()) # 分享 item["shares"] = self.get_default(select.xpath("//div[@class=’header-content’]/a[4]/div[2]/text()").extract()) # 赞 item["praises"] = self.get_default(select.xpath("//div[@class=’header-content’]/a[5]/div[2]/text()").extract()) # item["books"] = self.get_default(select.xpath("//div[@class=’header-content’]/a[6]/div[2]/text()").extract())
# 关注了 item["follow"] = self.get_default(select.xpath("//div[@class=’follow-block block shadow’]/a[1]/div[2]/text()").extract()) # 关注者 item["followers"] = self.get_default(select.xpath("//div[@class=’follow-block block shadow’]/a[2]/div[2]/text()").extract())
right = select.xpath("//div[@class=’stat-block block shadow’]/div[2]/div").extract() if len(right) == 3: item["editer"] = self.get_default(select.xpath("//div[@class=’stat-block block shadow’]/div[2]/div[1]/span/text()").extract()) item["goods"] = self.get_default(select.xpath("//div[@class=’stat-block block shadow’]/div[2]/div[2]/span/span/text()").extract()) item["reads"] = self.get_default(select.xpath("//div[@class=’stat-block block shadow’]/div[2]/div[3]/span/span/text()").extract())
else: item["editer"] = "" item["goods"] = self.get_default(select.xpath("//div[@class=’stat-block block shadow’]/div[2]/div[1]/span/span/text()").extract()) item["reads"] = self.get_default(select.xpath("//div[@class=’stat-block block shadow’]/div[2]/div[2]/span/span/text()").extract())
item["collections"] = self.get_default(select.xpath("//div[@class=’more-block block’]/a[1]/div[2]/text()").extract()) item["tags"] = self.get_default(select.xpath("//div[@class=’more-block block’]/a[2]/div[2]/text()").extract()) yield item # 返回item
上述代码,已经成功返回了item,打开setting.py文件中的pipelines设置,测试一下是否可以存储数据,顺便在 DEFAULT_REQUEST_HEADERS 配置一下request的请求参数。
setting.py
DEFAULT_REQUEST_HEADERS = { ‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8’, ‘Accept-Language’: ‘en’, "Host": "juejin.im", "Referer": "https://juejin.im/timeline?sort=weeklyHottest", "Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 浏览器UA" }
ITEM_PIPELINES = { ‘Juejin.pipelines.JuejinPipeline’: 20, }
本爬虫数据存储到mongodb里面,所以需要你在pipelines.py文件编写存储代码。
import time import pymongo
DATABASE_IP = ‘127.0.0.1’ DATABASE_PORT = 27017 DATABASE_NAME = ‘sun’ client = pymongo.MongoClient(DATABASE_IP,DATABASE_PORT) db = client.sun db.authenticate("dba", "dba") collection = db.jujin # 准备插入数据
class JuejinPipeline(object):
def process_item(self, item, spider): try: collection.insert(item) except Exception as e: print(e.args)
运行代码之后,如果没有报错,完善最后一步即可,在Spider里面将爬虫的循环操作完成
list_li = select.xpath("//ul[@class=’tag-list’]/li") # 获取所有的关注 for li in list_li: a_link = li.xpath(".//meta[@itemprop=’url’]/@content").extract()[0] # 获取URL # 返回拼接好的数据请求 yield scrapy.Request(a_link+"/following",callback=self.parse) Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
所有的代码都已经写完啦
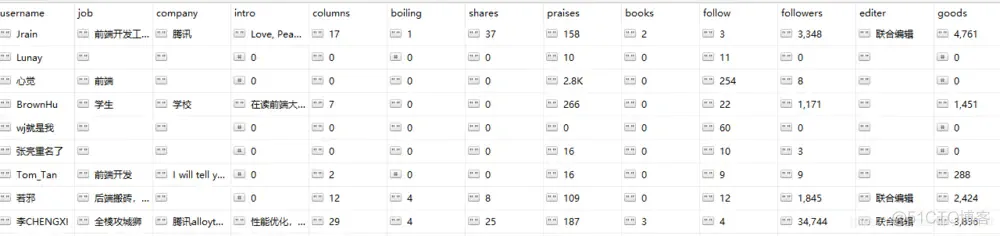
全站用户爬虫编写完毕
扩展方向

神龙|纯净稳定代理IP免费测试>>>>>>>>天启|企业级代理IP免费测试>>>>>>>>IPIPGO|全球住宅代理IP免费测试



