


记录mac使用chromedriver的解决办法
CSDN解决办法链接chr=webdriver.Chrome(r'/Users/a./opt/chromedriver/chromedriver') # 带完整路径的写法
我的插件所在地址/Users/a./opt/chromedriver/chromedriver
解决办法:
直接在新开窗口时候:r‘插件所在位置’
记录mac在终端使用jupyter notebook
把要使用的目录在终端打开
输入:jupyter notebook
一、基础知识
1、为什么要爬
爬取网络数据:如果需要的数据市场上没有,或者不愿意购买,那么可以选择爬虫方式,自己动手丰衣足食
爬虫Crawler,蜘蛛Spider,机器人Robot从搜索引擎机器人程序发展而来。虽然两者在功能上很相似,但是爬虫程序却可以通过分析遍历来的网页中含有的网页链接信息,自动获取下一步需要遍历的网页,这个过程可以自动的持续进行下去;且对网页内容进行解析。
互联网虽然很复杂,但其实就是一张大图——可以把每一个网页当作一个节点,把那些超链接当作链接网页的弧。
网络爬虫从任何一个网页出发,用图的遍历算法,自动地访问到每一个网页,并对其进行进行解析。
2、爬虫的作用
数据分析—-社交网络、情感分析、购物助手、排行榜数据等
自动下载—-图片、文档、音乐等自动操作—-抢票软件、自动关注
3、爬虫如何工作
网络爬虫模拟浏览器发送网络请求,接收请求响应,按照一定的规则,自动地抓取互联网信息的程序。遵循标准的HTTP协议利用超链接和Web文档检索方法遍历万维网
爬虫就是模拟浏览器的行为,越像越好,越像就越不容易被发现。
模仿浏览器的操作去收集数据
4、法律与道德问题
网络蜘蛛需要抓取网页,不同于一般的访问,如果控制不好,则会引起网站服务器负担过重。比如,淘宝就因为雅虎搜索引擎的爬虫抓取数据引起淘宝网服务器的不稳定。
好的网络爬虫,需要遵守robots协议(Robots Exclusion Protocol),即网络爬虫排除标准。
robots协议以文件的形式(robots.txt)存放于网站根目录下。它告诉爬虫网站中的哪些内容是不应被获取的,哪些是可以获取的。
robots.txt
robot.txt 中声明了哪些文件是可以获取的,哪些是不能获取的
如百度的:https://www.baidu.com/robots.txt

爬虫与反爬虫

最基本的:user-agent
二、网页基本知识
1、认识HTTP协议
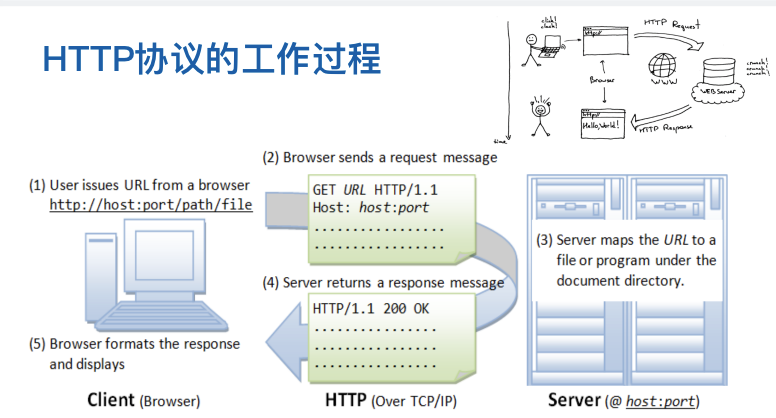
HTTP(超文本传输协议)是应用层上的一种客户机/服务器的通信协议,是Web的核心,由请求和响应构成。 协议:协议规定了通信双方必须遵守的数据传输格式,这样通信双方按照约定的格式才能准确的通信。

URL地址格式
HTTP协议基于URL访问服务器资源
URL(Uniform Resource Locator) :统一资源定位符
格式说明:URL由三部分组成
第一部分:协议,如http, https, ftp等
第二部分:主机地址及端口号(缺省端口为80)
第三部分:资源的具体地址,如目录和文件名等
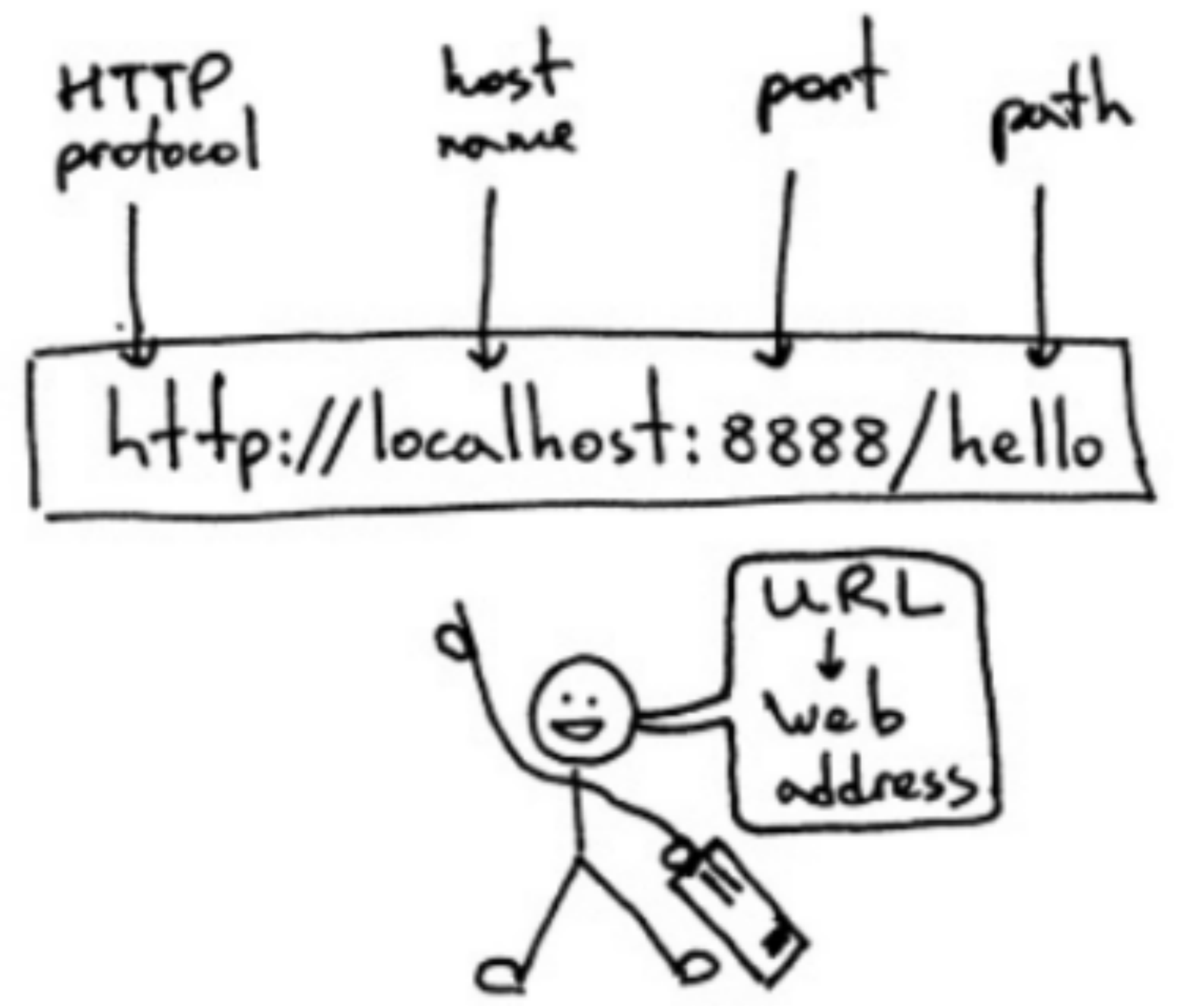
如:
https://pandas.pydata.org/docs/reference/index.html

user-Agent 请求头
如下在开发者工具中(F12)
network中反应的第一个,最下面
如,我的请求头 Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36

在爬虫和反爬虫的对弈中,User-Agent首当其冲
服务器端首先会根据User-Agent判断对方是哪种浏览器
依据浏览器发展的历程,服务器会针对不同浏览器发送其能接受的格式的HTML
Python程序发送的请求中User-Agent默认的取值是“Python……”,相当于明晃晃的告诉服务器“我是个爬虫!”,
因此爬虫第一步:必须对User-Agent进行伪装
在python爬虫中,首先要伪装User-Agent
HTTP响应 状态码

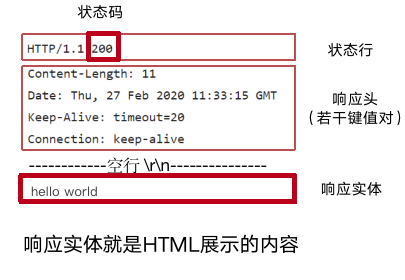
常用200,表示请求成功
2xx:表示服务器成功接收请求并已完成整个处理过程,常用200表示请求成功。
3xx:表示未完成请求,浏览器需进一步细化请求。例如:请求的资源位于另一个地址,需进行重定向,响应代码为302。
4xx:表示浏览器端的请求有错误,常用404表示服务器无法找到被请求的页面、403表示服务器拒绝浏览器的访问(权限不够)、405表示服务器不支持浏览器的请求方式等。
5xx:表示服务器端出现错误,常用500表示请求未完成,在服务器遇到不可预知的情况,属于服务器端程序错误 5xx是服务器端出问题,一般不常见。
2、网页组成(三大件)
- HTML
- CSS
- JS
HTML+CSS+JavaScript
复杂的网页主要由3部分组成
结构 (Structure)
表现(Presentation)
行为(Behavior)
HTML-结构:决定网页的结构和内容元素标记头部文件,元素标记网页名称,元素标记网页主体,<table>元素标记表格等<br/> CSS-表现(样式):设定网页的表现样式描述各类元素的视觉特征<br/> JavaScript:行为,控制网页的行为按钮动作等,通过</table></body>
静态网页和动态网页
静态网页:随着HTML代码的生成,页面的内容和显示效果就基本上不会发生变化了——除非你修改页面代码。
动态网页:是指跟静态网页相对的一种网页编程技术。动态网页的页面代码虽然没有变,但是显示的内容却是可以随着时间、用户请求数据的变化而发生改变的。
爬虫取到的页面仅仅是一个静态的页面,即网页的源代码,就像在浏览器上的“查看网页源代码”一样。一些动态的东西如JavaScript脚本执行后所产生的信息,是抓取不到的。
3、浏览器工具(F12)
推荐Chrome的F12
使用浏览器开发者工具查看网页请求
查找请求URL
查找请求head
使用浏览器开发者工具查看网页结构(这个很重要,爬到数据很容易,关键是把数据分类保存下来)

查看页面元素

常用的标签
常用属性:
class:特征标识
href:超链接地址(爬取目标)
src:图片下载地址(爬取目标)
三、使用request库编写基本爬虫
- 使用requests库请求数据
- 为请求添加参数
- 伪装请求报头
Python 提供了很多库来支持 HTTP 协议的网络编程,目前普遍使用requests库
requests 实现了 HTTP 协议中绝大部分功能,它提供的功能包括 Keep-Alive、连接池、Cookie持久化、内容自动解压、HTTP代理、SSL认证、连接超时、Session等很多特性,并同时兼容 Python2 和 Python3。
requests库中文文档 https://requests.readthedocs.io/zh_CN/latest/index.html
实例_从豆瓣爬取图片
演示:

1、获取URL
即获取所要内容的地址
在网页要查看的元素上,单击鼠标右键,选择“检查”
在Elements中,选中要复制的URL,进行复制
2、发出请求
使用requests.get(URL地址)发出请求
3、解析请求
请求返回 Response 对象,Response 对象是对HTTP 协议中服务端返回给浏览器的响应数据的封装
响应对象中的属性
状态码status_code——200 表示正常
编码方式 encoding(从HTTP的header中的charset字段中提取)
编码方式 apparent_encoding(从网页的内容中分析网页的编码方式,比encoding更加准确)
响应首部:headers(字典类型)
响应体:content、text
响应体
content、text、json
HTTP返回的响应消息中很重要的一部分内容是响应体,与响应体相关的属性有:content、text、json。
content 为 byte 类型,适合直接将内容保存到文件系统或者传输到网络中(声音、图像、视频、PDF文档等二进制数据)
text 是 string 类型,如一个普通的 HTML 页面,需要对文本进一步分析时,使用 text如果使用第
三方开放平台或者API接口爬取数据时,返回的内容是JSON格式的数据,那么可以直接使用 响应对象.json() 返回一个经过处理后的字典对象。
响应头

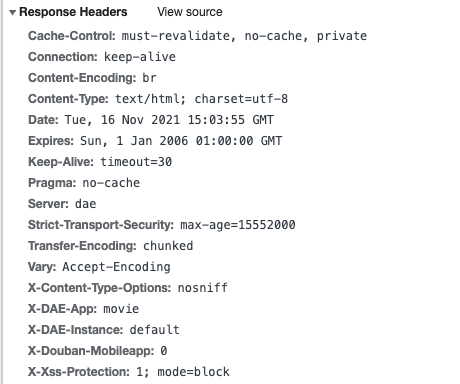
print("响应的状态码:{}".format(res.status_code))
print("该响应的数据类型为:{}".format(res.headers['content-type']))
print("该响应的数据量为{}字节".format(res.headers['content-length']))
4、保存数据保存数据
with open("tmp/图片.jpg", "wb") as f:
f.write(res.content) #res.content为二进制类型的响应数据
w表示写,b表示二进制文件
注意保存到指定路径下的时候,文件要存在,否则会下图

解决中文乱码
将响应的apparent_encoding 编码送给响应的encoding属性:
res.encoding = res.apparent_encoding !!!

2、为请求添加参数
请求参数:向请求提交的待处理数据
构建请求查询参数
get请求:将参数附加在URL请求地址中(请求行)
post请求:将参数附加在请求实体中
get请求
将参数附加在URL请求地址中(请求行)
很多URL都带有很长一串参数,称这些参数为URL的查询参数,用”?”附加在URL链接后面,多个参数之间用”&”隔开
以百度搜索为例,如何进行带参数请求?
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=python&fenlei=256&rsv_pq=8876fa4d0015d0ce&rsv_t=4cd8T9fffLAqYmzGhd5p%2FF6ntO1iZckFwgxj3Fa8bhMt6Bmg6
方法1
构造URL
# 采用构造URL方式访问 res = requests.get('http://baidu.com?wd=python') #url?key=value
# 打印输出该 URL,能看到URL已被正确编码 print(res.url)
'http://baidu.com/?wd=python'
方法2
将参数放在params参数中传递,适用于参数较多的场景
# 采用构造URL方式访问 response = requests.get("https://baidu.com", params={'wd': 'python'})
# 打印输出该 URL,能看到URL已被正确编码 print(res.url)
post方式
将参数附加在请求实体中
requests 可以非常灵活地构建post请求需要的数据,如果服务器要求发送的数据是表单数据,则可以指定关键字参数 data;
如果要求传递 JSON 格式字符串参数,则可以使用json关键字参数,参数的值都可以字典的形式传递。
方式1
作为表单数据传输给服务器
# 作为表单数据传输给服务器
# URL: www.httpbin.org, 这是一个简单的 HTTP 请求和响应服务 payload = {'key1': 'value1', 'key2': 'value2'} res = requests.post("http://www.httpbin.org/post", data=payload) print(res.text)

方式2
作为 json字符串格式传输给服务器
JSON格式的优势,数据可以嵌套
# 作为 json 格式的字符串格式传输给服务器 import json
payload = {'key1': 'value1', 'key2': 'value2'} res = requests.post("http://www.httpbin.org/post", json=payload) # 查看相应内容,注意看Content-Type的变化 print(res.text)

3、伪装请求头 user-agent
requests 可以很简单地指定请求首部字段Headers,直接传递一个字典对象给参数 headers 即可。
user-agent(用户代理):HTTP协议中的一部分,属于请求头,作用是描述发出HTTP请求的终端的一些信息。
网站常用这个参数来分辨爬虫,对于不是正常浏览器的用户进行屏蔽。
修改user-agent:储存系统和浏览器的型号版本,通过修改它来伪装为浏览器,以此来蒙蔽服务器
# 请求一个返回Json格式数据的API hd = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:80.0) Gecko/20100101 Firefox/80.0'} res = requests.get('https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8', headers = hd) # 查看文件类型 print(res.headers['Content-Type']) #application/json; # 以JSON格式查看内容 print(res.json())
四、使用BeautifulSoup库解析网页
requests 库请求的数据结果
JSON 格式,数据对开发者来说最友好
HTML 文档,最为常见
XML 格式
BeautifulSoup :一个用于解析 HTML 文档的 Python 库,通过 BeautifulSoup,只需要用很少的代码就可以提取出 HTML 中任何感兴趣的内容,此外,它还有一定的 HTML 容错能力,对于一个格式不完整的HTML 文档,它仍可以正确处理。
BeautifulSoup 用来解析网页
1、使用前准备工作
pip install bs4
官方文档:http://beautifulsoup.readthedocs.io/zh_CN/v4.4.0
HTML 结构

它由很多标签(Tag)组成,比如 html、head、title等等都是标签
一个标签对构成一个节点,比如 …是一个根节点
节点之间存在某种关系,比如 h1 和 p 互为邻居,他们是相邻的兄弟(sibling)节点
h1 是 body 的直接子(children)节点,还是 html 的子孙(descendants)节点
body 是 p 的父(parent)节点,html 是 p 的祖辈(parents)节点
嵌套在标签之间的字符串是该节点下的一个特殊子节点,比如 “hello, world” 也是一个节点,只不过没名字。
2、如何使用BeautifulSoup
构建一个 BeautifulSoup 对象需要两个参数
第一个参数:要解析的 HTML 文本字符串
第二个参数:告诉 BeautifulSoup 使用哪个解析器来解析 HTML

BeautifulSoup 负责操作数据(增删改查)
BeautifulSoup优点:API人性化,支持CSS选择器
BeautifulSoup缺点:基于HTML DOM树,会载入整个HTML文档,解析整个DOM树,因此时间和内存开销都会很大
BeautifulSoup用来解析 HTML较为简单的页面
3、标签选择器
- 获取标签 soup.标签名
- 获取标签间文字:soup.标签名.string
- 获取属性字典:soup.标签名.attrs
- 获取属性取值:soup.标签名[属性名]

BeatifulSoup 主要的数据类型
beautifulSoup:代表整个 HTML 文档
tag:每个标签节点
navigableString:包裹在Tag对象中的字符串
print(type(soup)) # bs4.BeautifulSoup print(soup) # 无格式 print(soup.prettify()) #缩进对齐格式
获取标签

获取标签间的文字:
提取标签间文字的方法
.string:返回当前节点中的内容,但是当前节点包含多个子节点时,.string不知道要获取哪一个节点中的内容,故返回空
.text:返回当前节点所包含的所有文本内容,包括当前节点的子孙节点

获取属性字典

获取属性取值

使用标签选择器实例

- .string 返回当前节点内的内容,假如当前节点包含多个自节点时候,不知道获取哪一节点内的内容,故返回值为空
- .text 返回当前节点内包含的所有文本内容
- 包括当前节点的子节点
4、遍历DOM树
可以对元素的子元素、父元素、兄弟元素等进行导航,从而遍历整个网页
contents属性:直接子节点列表(文本、节点)
descendants属性:子孙节点
parent属性:父节点
parents属性:祖先节点
next_sibling属性:下一个兄弟节点
previous_sibling属性:上一个兄弟节点

下行遍历



上行遍历

平行遍历

搜索文档树
搜索文档树是通过指定标签名来搜索元素,还可以通过指定标签的属性值来精确定位某个节点元素
find_all()
find()
这两个方法在 BeatifulSoup 和 Tag 对象上都可以被调用


5、BeautifulSoup库网络爬取实战
学术会议论文集爬取

6、CSS选择器
比单纯的标签选择器更具体
标签名.classname



7、实战_利用BeautifulSoup爬取猫眼
换页的信息隐藏在URL中,因此可以通过修改URL的参数来实现爬取
url = '[http://maoyan.com/board/4?offset='](http://maoyan.com/board/4?offset=') + str(i*10)
五、自动化爬取动态网站的方法
- selenium
- 安装ChromeDriver,即Chrome浏览器的驱动
- 
测试selenium自动执行
应对JavaScript等解决不了的反爬虫技术
跳转被隐藏在JavaScript代码中没有URL,即不能修改页面参数来实现换行
中国大学2020排名
六、反爬虫

最后,请利用所学的实践一波吧

神龙|纯净稳定代理IP免费测试>>>>>>>>天启|企业级代理IP免费测试>>>>>>>>IPIPGO|全球住宅代理IP免费测试



